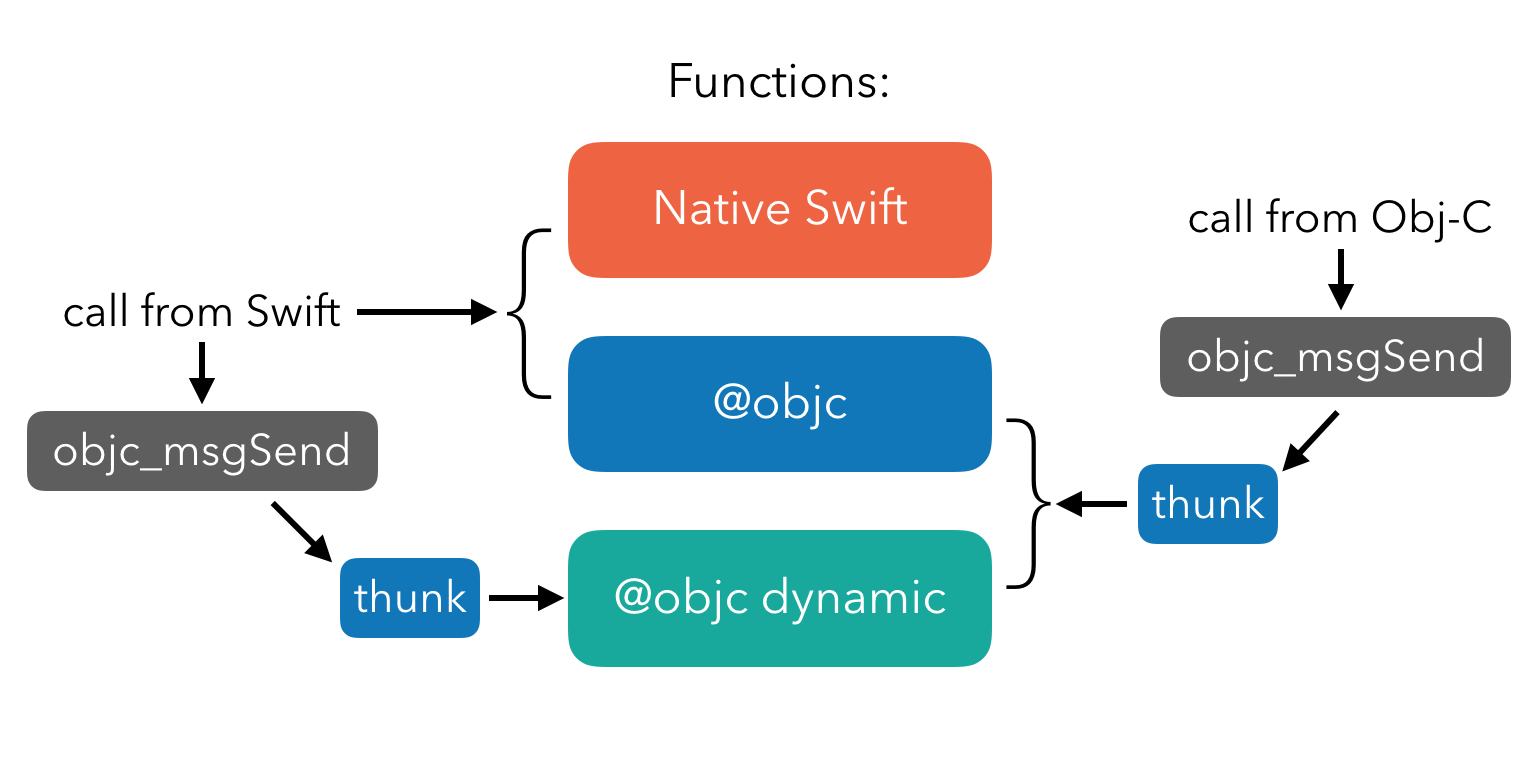
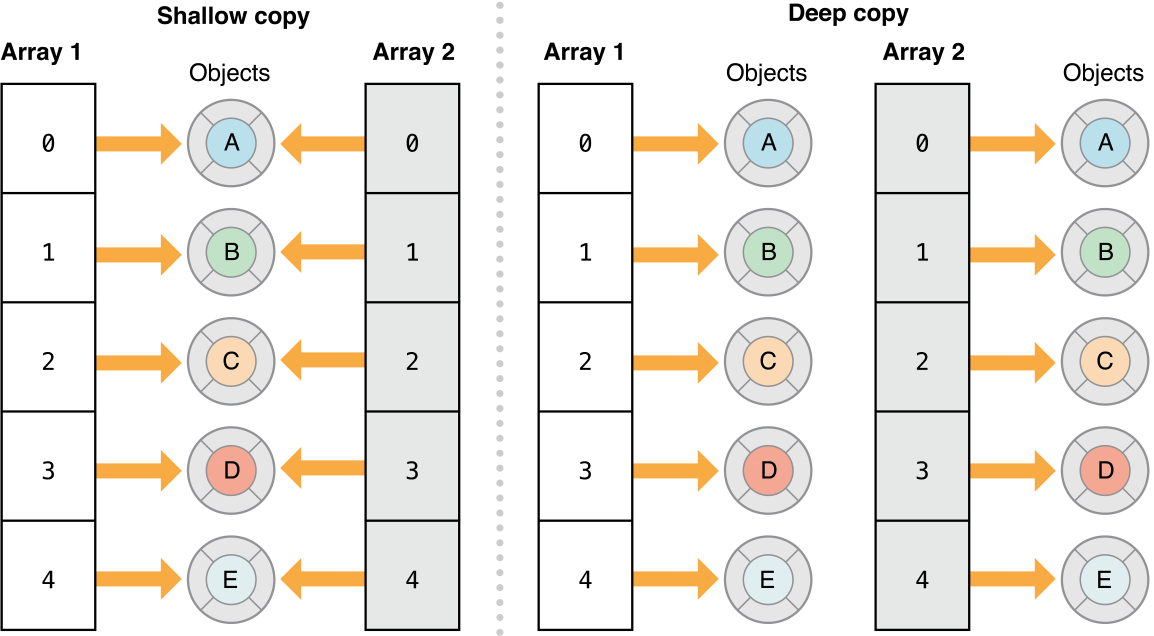
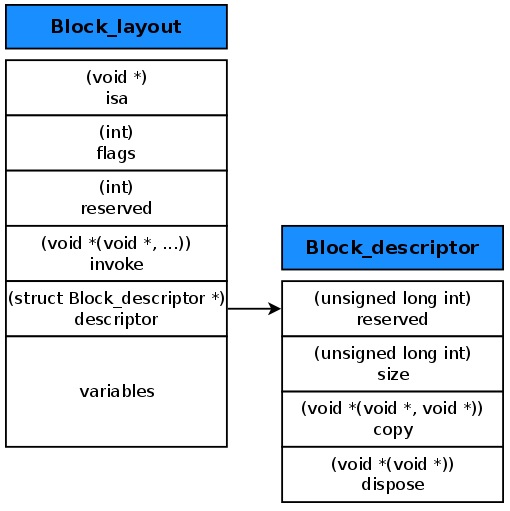
写过 Swift 的同学都知道,在 Swift 中有一种 optional 类型的数据,它可以通过 ! 进行强制解包,而当它强制解包不成功的时候就会导致程序出现崩溃问题。
(说到这里可能会有同学认为在代码中就不应该使用强制解包的语法,那请问 Swift 为什么要推出这种语法呢?其实当我们能够百分比确认某一个变量或业务的状态,那我们就应该使用强制解包,这个时候强制解包的好处就是能够帮助我们在开发阶段提前把问题暴露出来,并且在代码的使用上也更方便。)
我们的应用由于需要在 Extension 和 Host App 之间进行数据共享,所以我们开启了 App Groups 这个特性。而在 Swift 代码中我们是这样去使用:
1 2 3
let store =UserDefaults(suiteName: "group.com.yourcompany.product")! // or let url =FileManager.default.containerURL(forSecurityApplicationGroupIdentifier: "group.com.yourcompany.product")!
由于使用重签名的企业证书并没有包含这个的 App Group 的特性,所以最后会导致当我们手机安装重签名的包之后并且在启动后运行到这段代码的时候因为强制解包失败导致应用直接崩溃。 所以一般的应用即使在业务上没有相关的需求,我依旧建议大家也应该增加这样的特性功能,并且利用这个特性来让其他人没有那么容易就能对你的应用进行重签名之后拿去使用。
The default value of this property is true, which lets container view controllers know that they should adjust the scroll view insets of this view controller’s view to account for screen areas consumed by a status bar, search bar, navigation bar, toolbar, or tab bar. Set this property to false if your view controller implementation manages its own scroll view inset adjustments.
官方文档的意思当在 UIViewController 上添加 UIScrollView 的时候,会根据当前页面的 status bar、 search bar、navigation bar、toolbar 或 tab bar 来修改 UIScrollView 的内容区域。但是这个阶段的 UIViewController 比较蠢,不管任何情况下都会修改 UIScrollView 的偏移量。
Submits a block to a dispatch queue for synchronous execution. Unlike dispatch_async, this function does not return until the block has finished. Calling this function and targeting the current queue results in deadlock.
// Person @interface Person: NSObject @property (nonatomic, copy) NSString * name; @end @implementation Person @end
Person * aPerson = [Person new]; Person * bPerson = [aPerson copy];
Xcode 直接奔溃了:
1 2
// 崩溃 *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[Person copyWithZone:]: unrecognized selector sent to instance 0x60000000d5f0'
为什么我们对一个 Person 对象使用了 copy,Xcode 确报的是找不到 copyWithZone: 这个 selector 的错误。